2019/4/30 12:02:57
Synopsys 技术营销经理 Yudhan Rajoo
深度学习计算的复杂性
目前最流行的深度学习技术是卷积神经网络 (CNN)。CNN 采用未压缩的数据帧
(例如具有高度“h”、宽度“w”和深度“d”的图像),并使用二维滤波器对图像进
行卷积,创建一个值矩阵,随后使其通过充分连接的分类网络进行推理。卷积
运算本质上是乘积累加 (MAC) 计算,可以用图 1 所示的等式表示。
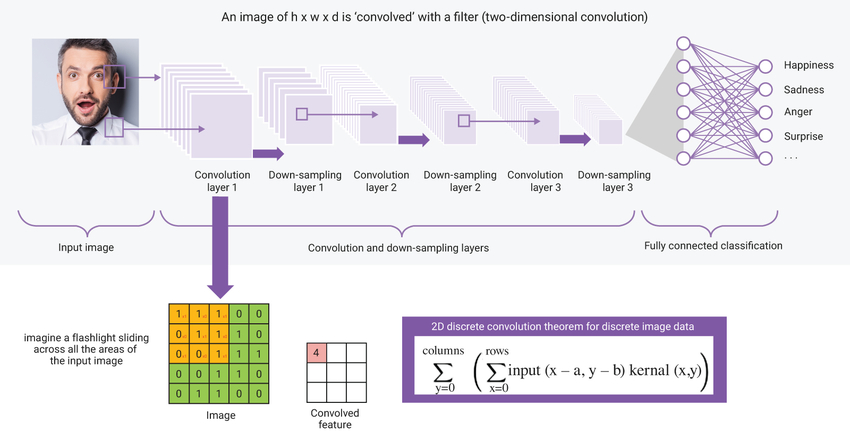
图 1:CNN 的卷积运算等式和运用
过去,MAC 计算遇到的问题借助早期用于机器学习的传统 DSP 和 GPU 得到部
分解决,但业界很快意识到这些架构需要经过专门的改进才能有效地达成性能、
功耗和面积之间的微妙平衡。对于 CNN 函数,一些矢量 DSP 可为卷积提高面
积效率,但缺乏必要的速度和功耗效率。GPU 的吞吐量效率很高,但是光影芯
核数量的增加会消耗大量的芯片面积和功耗。最近出现了一些采用 FPGA 获得
成功的案例,但此类应用仅限于芯片面积要求不太严格的数据中心。专用的
CNN 引擎(例如 DesignWare® 嵌入式视觉处理器中的引擎)通过定制逻辑
解决了这一困境,该逻辑可在小面积和低功耗预算范围内,每周期执行多达
3520 项 MAC。
CNN 引擎实现面临的挑战
CNN 引擎(神经网络处理器)是一种新型怪兽,只有经受住战斗考验的勇士
才能将其降服。在实现这些模块时,如果选了错误的方式,就可能给项目进
度带来大麻烦。 因此,利用能够在设计周期内为过程校正提供灵活性的基础
IP 开展设计是成功推出产品的必要之举。
布局迭代
机器学习模块的物理设计实现通常需要布局迭代来确定在给定芯片面积下的
最佳布局和逻辑层次。迭代可能需要对芯核面积和宏本身的高宽比加以修改,
以便可以将较慢的宏靠近逻辑层次结构放置。为了解决这种迭代运转问题,
出于时序和高宽比的权衡考虑,必须在编译器中进行各种比例的存储器分割。
反过来,逻辑层次结构的相对位置受绕线路径资源(可用于将这些层次结构
组装到给定空间)的影响。虽然顶层设计人员已经为模块定义了顶层绕线的
限制条件,但是针对特定逻辑库调节电源接地 (PG) 网格也可以优化芯核密度。
缺乏启动 PG 网格设计的方法可能会导致实现工作延迟。
MAC 拥塞
解决了宏模块之后,接下来的挑战就是管理逻辑区域中的布局和布线拥塞问题,
同时调整每 MHz 功耗目标的设计。MAC 模块的引脚密度高于常规且网络连接
密集,导致绕线资源拥塞,因而“声名狼藉”。表示为原理图时,MAC 模块在数
据通过时具有自然的三角形形状,这就是为什么最理想的结果通常都是通过手
动放置数据路径元素来实现的。EDA 工具在弥合 MAC 模块的完全自定义布局
与算法衍生的单个单元布局之间的差距方面取得了良好进展,这些布局也设定
了几何尺寸缩小后的工艺设计规则。但是,某些 EDA 工具需要兼容的标准单元
结构才能完成解决方案。无论是手工放置元件块还是依靠工具放置,都需要更
大且具有不同电路拓扑和尺寸的多路加法器、多路复用器、压缩器和顺序单元。
实现 PPA 的时间差异化
设计期限很长,而流片期限却很短。设计周期的压缩导致没有时间在先进工艺
节点逐渐增加设计团队。整合完成了硅设计的成熟 IP,以及从一开始就能开始
实施工艺的工具流程,是在竞争激烈的市场中获胜的“必备方案”。随着节点的
不断缩小,芯片代工厂用于人工智能 SoC 的选项变得非常有限。更加有限的是
代工厂提供的逻辑库和存储器设计套件中的选项。这引出了一个问题:使用代
工厂默认设计套件的 PPA 设计如何在市场中脱颖而出? 要想推动 PPA 超越常
见的优化策略和基础实现工具包达到的极限,关键在于采用真正独特的 IP 解决
方案。
攻克挑战
选对构建模块就成功了一半
在实现 PPA 和人工智能 SoC 上市时间目标的道路上,设计工程师们遇到了重重
障碍,必须作出争分夺秒的决策。针对逻辑库和存储器编译器的解决方案可以
帮助设计人员着手应对实现 CNN 引擎以及采用 AI 技术的 SoC 带来的挑战。例如,
如果采用标准工具算法不足以攻克实现难题,那就务必要具备多个利用 EDA 工
具优化功能并提供手动干预灵活性的逻辑单元选项。Synopsys 的基础 IP 产品组
合中包括 HPC 设计套件。该套件是逻辑库单元和存储器的集合,已在先进节点
上与 EDA 工具共同经过优化,旨在突破任何设计的 PPA 极限,并针对支持 AI 的
设计进行了优化。Synopsys 除了供应种类丰富且经过硅验证的产品组合用于实
现理想 PPA 目标之外,还支持满足个性化设计需求的定制服务,使其业务比任
何其他产品更灵活(图 2)。
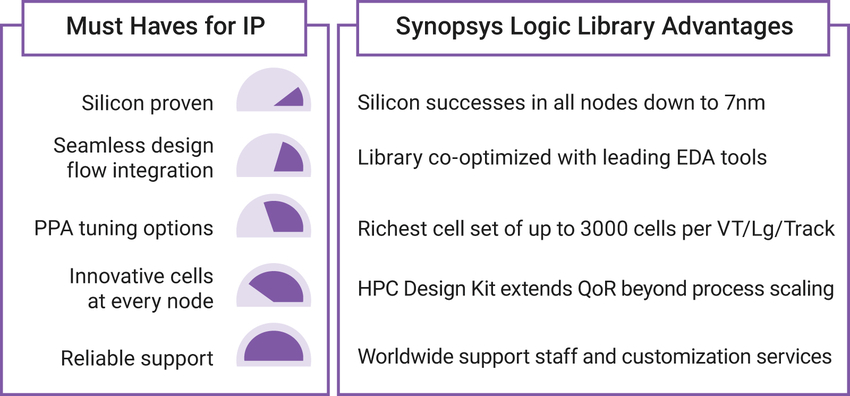
图 2:差异化逻辑库 IP 的要求和优点
设计流程快速入门
使用 EDA 供应商提供的基础 IP 解决方案最重要的优势在于互操作性。这意味着
设计人员可以使用 IP 附带的脚本在最尖端的工艺节点上进行工作渠道清理流程,
并且不会浪费增效时间。设计人员使用 EDA 供应商的基础 IP 时,也可以使用经
过严格测试电源地网格布线。电源地网格布线能让设计人员提早开始设计探索、
利用标准单元架构中的特殊规定,并利用额外的路由路径资源获取信号,而不会
影响设计的电源完整性。完成后,即可全面展开布局布线。
在 DesignWare ARC® EV6x 嵌入式视觉处理器芯核中,经过几次迭代后,利用正
确的高宽比可以提供 500MHz 的最佳绕线利用率。对于频率增加到 800MHz 的
设计,仅靠增加具有相同高宽比的平面布局不足以实现设计收敛。在这种情况下,
不仅需要不同的高宽比用于存储器分割,而且还需要具有更大位数和不同周边设置,
且速度更快的存储器架构。Synopsys 的 HPC 设计套件提供各种编译器,可以轻松
地将性能从 500MHz 扩展到 800MHz,并为每个性能级别提供优化的布局。 提供
种类广泛的基础 IP 供设计人员随手取用,为优化提供了更多空间,减少了布局规
划迭代,最终加速了设计收敛。

图 3:具有 CNN 引擎的 DesignWare ARC EV6x 上的布局迭代示例表明,面积非常宝贵时可以实现 500MHz 的灵活性,而在优化了性能的设计中则可达到 800MHz
和工具一同优化后充裕的单元库
事实证明,库中和 EDA 工具共同经过优化后数量充裕的单元库是实现 PPA 和管理拥塞的关键组件。库与工具共同优化之后,逻辑库架构师就能够深入了解先进综合和绕线算法。这就促使库设计人员决定要纳入哪些单元以及如何布置这些单元。该工具的算法设计人员可以合力在工具中引入功能,确保使用新的逻辑单元类型之后能够获得出色的结果。IP/EDA 供应商的幕后工作减少了 SoC 设计人员所需的工作量,让他们能够集中精力设计实现任务的其他方面。多重图形 FinFET 节点使工具和库的结合效果更加突出。使用较小工艺技术的 SoC 设计人员可以利用库单元的优势。这些库单元的引脚布局(特别是高输入复杂单元的引脚布局)已经过优化,可以利用最新的绕线创新,最终在设计层面实现更快的绕线闭合。
可以根据单元的面积和速度的比率在综合算法中完成决策。这些算法只要在逻辑库中有足够的选项,就可以产生最优的电路拓扑。使用 Synopsys 逻辑库时,即使是大型复杂单元也可以在综合时无缝集成到 EDA 流程中,从而减少了人工干预。将多位与压缩器单元组合在一起的特种宽幅多路复用器有助于缩短设计的总净长度。宽幅多路复用器减少了所需的绕线轨道数量,有助于节省面积和缓解拥塞。压缩器、加法器和多路复用器专用库中的多个电路拓扑可确保综合过程中始终都为各个具有不同乘法器尺寸的架构找到最佳解决方案。低功耗型号的多位触发器和多路复用器确保功耗不会受到影响,而较大的设备尺寸则用于缓解拥塞。使用具有更多位数的 Booth 多路复用器和数据路径算术单元,将多个布尔逻辑组合成一个优化至极的单元,也能让华莱士树状结构从中受益。喜欢在设计中使用手动放置的结构化数据路径,或者偏爱使用脚本来交换单元以进行功率恢复的设计人员可以从 HPC 设计套件库中受益。该库为不同设备尺寸的顺序和组合功能提供了广泛的选项。
结语
Synopsys 的 HPC 设计套件已针对人工智能/机器学习应用进行了改善(图 4)。与通用基础 IP 解决方案相比,新套件可以为 DesignWare 嵌入式视觉处理器节省高达 39% 的功耗。使用 HPC 设计套件进行权衡调整还可以使速度提高 7%,并且 CNN 模块可以节省 28% 的功耗。
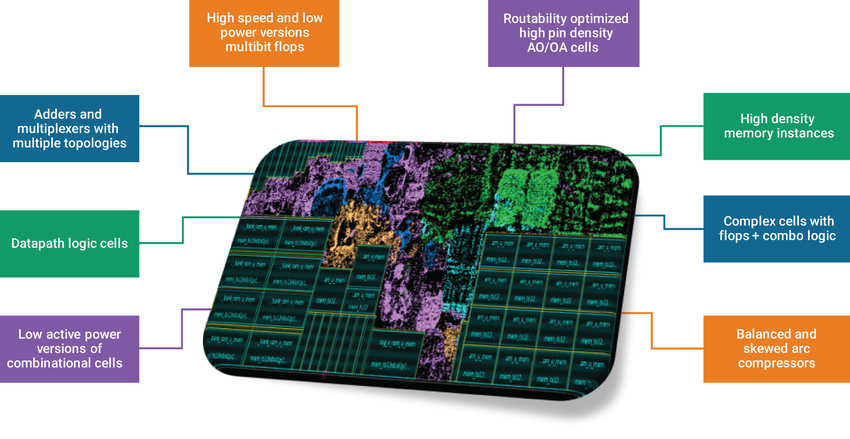
图 4:用于人工智能和机器学习应用的增强型 HPC 设计套件
Synopsys DesignWare HPC 设计套件是各个企业的不二选择,它支持客户在高级工艺节点中完成硅晶设计,同时支持提供定制服务,让您的设计变得与众不同。
声明:本网站部分文章转载自网络,转发仅为更大范围传播。 转载文章版权归原作者所有,如有异议,请联系我们修改或删除。联系邮箱:viviz@actintl.com.hk, 电话:0755-25988573

